
Druid / Imply 소개
●2010년 Apache 프로젝트로 시작
●시계열 데이터에 대한 효과적인 저장 및 집계를 실시간으로 지원하기 위해 설계
●스트리밍, 핀테크, 광고 등의 Digital Native 회사들이 다수 참여
●2015년 Druid 개발자들이 설립한 Series D 단계의 회사
● Apache Druid 기반의 데이터 분석 플랫폼 제공
·엔터프라이즈 기능(성능 개선, 보안 기술)
·관리 편의성, 모니터링
·시각화
●스트리밍, 핀테크, 광고 등의 Digital Native 회사들이 다수 참여
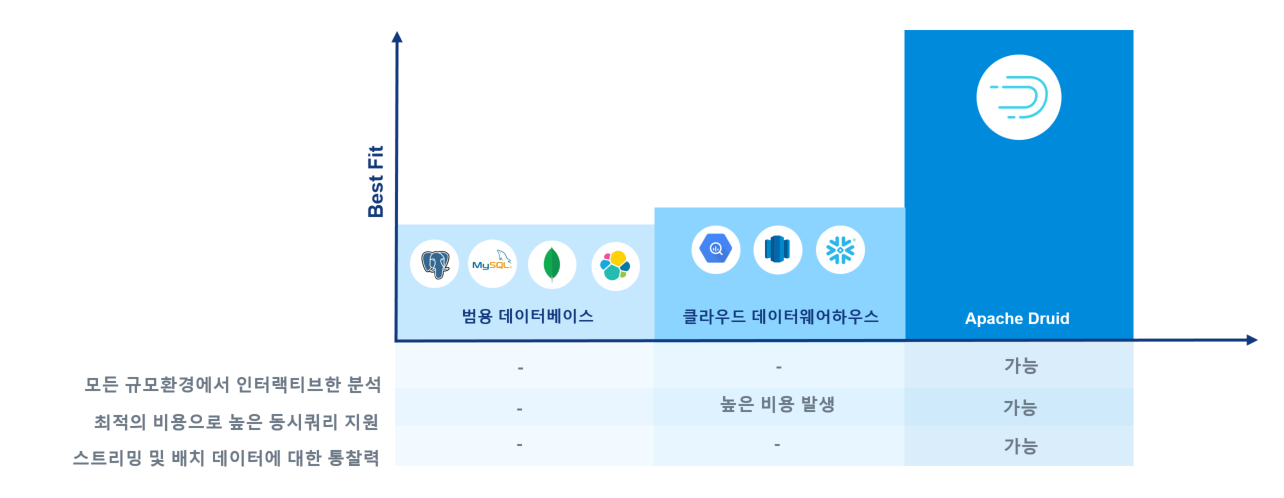
최신 데이터 분석 트렌드 달성 요구사항


실시간 대용량 데이터 분석을 위한 기술 요소
●
PB 규모의 데이터 처리
●
초당 1,000개 이상 쿼리의 빠른 응답 지원
●
실시간 및 과거 데이터 연계 분석
기술 요소 달성을 위한 필요조건

지속적으로 다량의 분석 쿼리를 발행하는
반응형 분석
반응형 분석

비용효율적으로 높은 동시성을 지원하는
데이터 플랫폼
데이터 플랫폼

실시간 데이터 분석과 이를 위한 과거데이터 집계를
동시 지원하는 아키텍처
동시 지원하는 아키텍처
기존 기술 대비 차이점
Apache Druid 아키텍처

대규모의 환경에서 1초 미만의 쿼리 성능 제공
최신 어플리케이션에 필요한 데이터 처리 및 동시성 제공
ㅡ
최신 요구사항을 지원하기 위한 하이브리드 아키텍처
ㅡ
비용효율적인 스토리지 엔진
ㅡ
다양한 방식으로 어플리케이션과 연결 (JDBC, API 등)
실시간 데이터의 수집
실시간 데이터를 과거 데이터와 집계하여 빠르게 분석
ㅡ
스트리밍 기술과 연계
ㅡ
실시간 데이터의 실시간 처리
ㅡ
손쉽게 확장이 가능한 아키텍처
ㅡ
일관성(Eventual Consistency) 보장
중단없는 신뢰성
다운타임 걱정없는 운영
ㅡ
지속적인 백업
ㅡ
자동 복구
ㅡ
자동 리밸런싱
Imply 플랫폼
Apache Druid를 위한 완벽한 경험
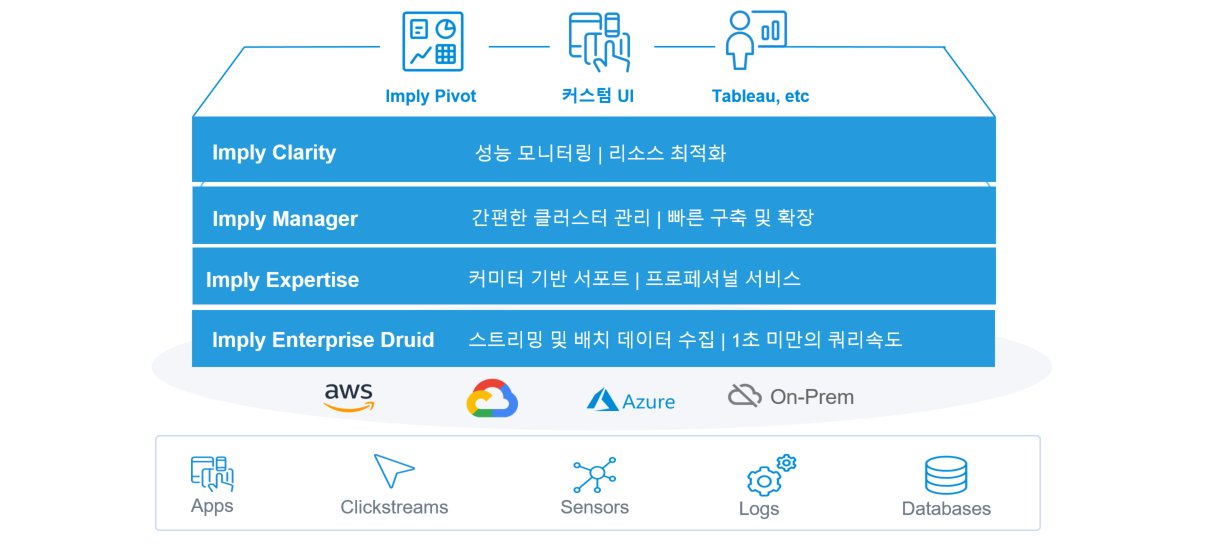
하이레벨 데이터 아키텍처

Imply Dashboard 및 DataCube 사용 예시

●
1초 미만의 쿼리속도로 드래그인 드롭 분석 및 시각화
●
사용자별 대시보드 구성
●
멀티디멘션 및 메트릭 구성
●
다양한 차트 제공

선두 기업들은 Druid의 강력한 분석을 위해 Imply를 선택합니다.
Media/Ads

Communications

Retail

Financial
Services/Fintech
Services/Fintech

Gaming

Networking

Technology

Security




